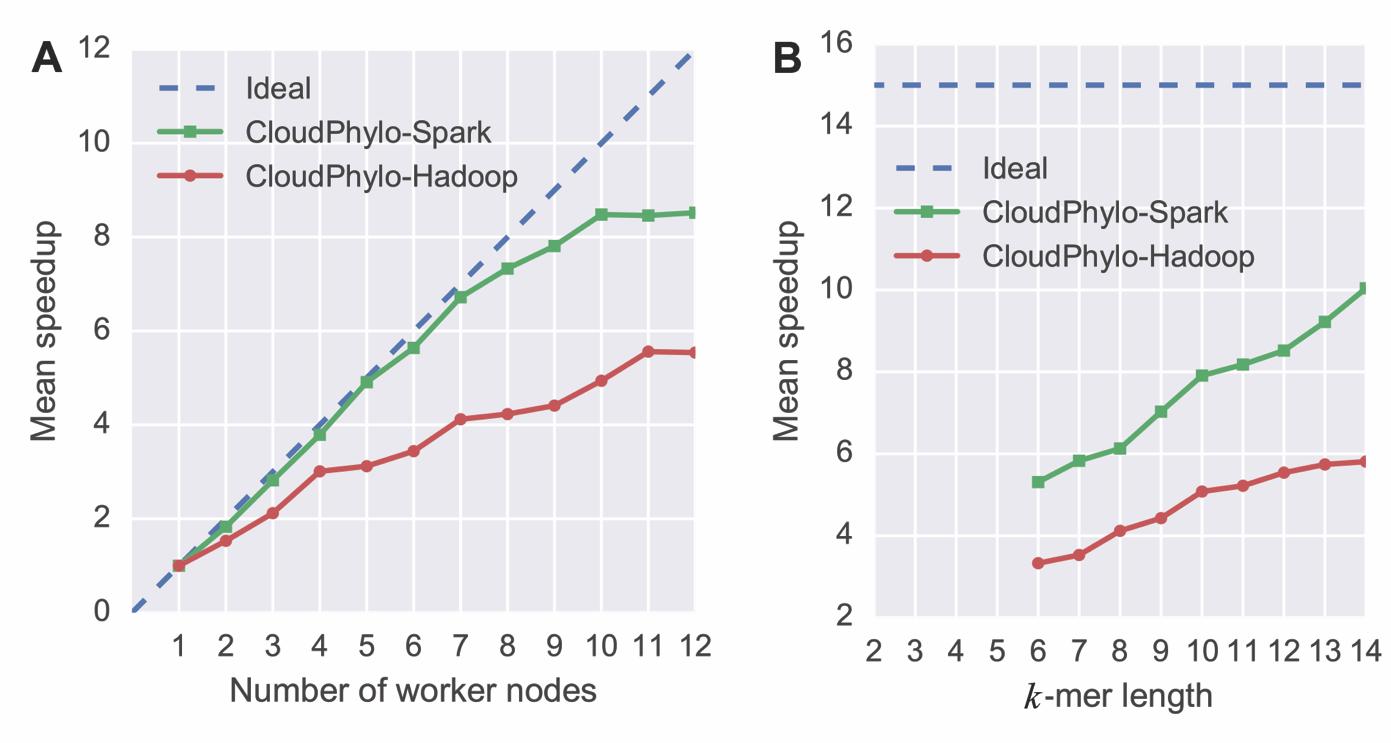
構建系統發育樹是分子進化研究中分析物種間進化關系的基礎步驟與重要環節。隨著生物大數據時代的到來,傳統的建樹工具在使用大數據集構建系統發育樹時需要消耗更多的計算資源且運行時間超長,使得科研工作者無法快速高效地進行分子進化分析。為此,生命與健康大數據中心(BIG Data Center;http://bigd.big.ac.cn)利用Spark云計算技術,于近期開發了一款適用于大數據集的系統發育樹構建工具——CloudPhylo。Spark是一種新的分布式云計算框架,它實現了MapReduce分布式并行算法。基于Spark框架的程序在運算過程中可高效地將中間輸出結果保存在內存中,大大降低了因為頻繁讀寫文件造成的損耗。因此,與傳統的Hadoop框架相比,Spark能更好地應用于需要反復迭代的大數據分析任務。
 該項研究工作獲得了國家高技術研究發展計劃(2014AA021503和2015AA020108)和中國科學院國際合作局國際大科學計劃(153F11KYSB2016008)等基金資助。
該項研究工作獲得了國家高技術研究發展計劃(2014AA021503和2015AA020108)和中國科學院國際合作局國際大科學計劃(153F11KYSB2016008)等基金資助。