


北京基因組所(國家生物信息中心)多組學數據資源體系建設取得系列重要進展
在2022年1月正式出版的國際生物數據庫頂級期刊《核酸研究》(Nucleic Acids Research)2022年度數據庫專刊上,中國科學院北京基因組研究所(國家生物信息中心)國家基因組科學數據中心(CNCB-NGDC)共有10篇論文集中亮相,包括1篇整體介紹和9篇數據庫論文,展示了國家生物信息中心多組學數據資源體系建設的最新成果,并連續5年被該刊稱為與美國國家生物技術信息中心(NCBI)、歐洲生物信息學研究所(EBI)并列的全球主要生物數據中心。
2021年,CNCB-NGDC與共建單位以及30多家合作單位密切協同,進一步更新和完善核心數據庫資源(BioProject、BioSample、GSA、GWH、GVM、GEN、MethBank、非編碼RNA、新冠病毒資源信息庫、生物多樣性等),同時開發了腦疾病知識庫BrainBase、癌癥單細胞表達譜數據庫CancerSCEM、細胞藥物反應知識庫CeDR Atlas、細胞分類庫Cell Taxonomy、分子序列組分數據庫CompoDynamics、表觀基因組關聯分析平臺EWAS Open Platform、再生知識庫Regeneration Roadmap、單細胞甲基化庫scMethBank、生命科學文獻庫OpenLB等,涉及單細胞組學和精準醫學研究等多個前沿領域,建成涵蓋國家人類遺傳資源、重要戰略生物資源、在線分析工具等在內的多組學數據資源體系,形成了組學“數據—信息—知識”一體化資源系統。該資源體系的建設,解決了長期以來我國基因組科學數據匯交共享嚴重依賴國際數據庫的問題,為國家基因組科學數據的匯交共享、安全管理和挖掘利用提供了重要支撐,入選國家“十三五”科技創新成就。
CNCB-NGDC匯聚全球數據,為國內外用戶提供一站式數據遞交和中英文服務,發布的數據編號被Springer Nature、Elsevier、Wiley、Taylor & Francis、Cell等全球主要出版集團認可。截至2021年底,組學原始數據管理體系(GSA Family)已匯交科技項目4200多個,數據量超11 PB,來自471家單位2082個用戶,相關數據發表于276種國內外期刊的841篇文章。2019新冠病毒信息庫(RCoV19)不斷更新,目前已收錄新冠病毒序列近700萬條,為全球179個國家/地區140多萬名訪客提供數據服務,累計數據下載超21億條,為中國—世衛新冠病毒聯合溯源研究提供基因組及其變異數據分析支撐,在病毒演化分析、監測、溯源等方面發揮了重要作用。
CNCB-NGDC的建設得到科技部、財政部、中國科學院、國家自然科學基金委、一帶一路國際科學組織聯盟、國際生物科學聯合會等的資助。
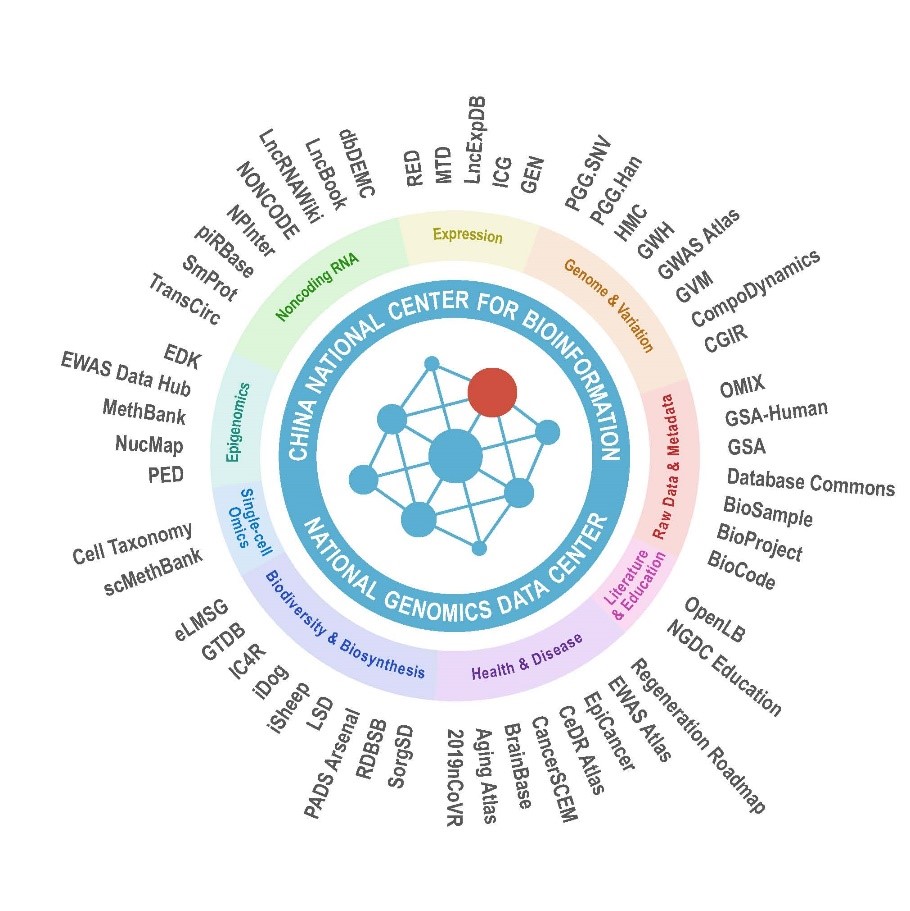
CNCB-NGDC多組學數據資源體系


